新手如何用Python玩转ChatGPT API,详细讲解
ChatGPT火的不行,很多人已经在这风口上赚了一桶金,那么做为新人的的我们如何去调用ChatGPT API,过把瘾呢?
下面本文就详细的讲解一下如何使用Python来调用ChatGPT API。更多的详细资料,请去ChatGPT官方文档查阅,地址:https://platform.openai.com/docs/introduction
一、安装OpenAI,这个大家都懂的。
pip isntall openai
二、注册一个ChatGPT账号
注册了帐号之后,然后获取到KEY,这里网上有很多教程,或者有很多渠道可以弄到账号,这里我就不废话了。
三、使用Python调用ChatGPT
1、官方示例:
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)这是基本的代码结构,model和messages是必选参数,model代表模型,官方有很多模型,选适合自己的就好。messages是一个消息对象数组。每个对象都包含了一个角色('system'、'user'、'assistant')和'content'。对话都是由这样形式的一条消息或者多条消息组成的。
2、参数解释:
a、system:系统设定,一般是用来指定ChatGPT的角色(比如告诉它是一位老师,一位编程高手、一位面试官等。) b、user:表示用户 c、assistant:表示ChatGPT对用户的回复 d、content:内容
3、简单对话
如果我们要求不高,只是简单对话,那么我们通过下面的代码就可以实现。
import openai
openai.api_key = 'api_key'
q= [{"role": "user", "content": "你好"}]
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0301",
messages=q
)
msg = rsp.get("choices")[0]["message"]["content"]
print(msg)运行之后效果如下图:
4、启用上下文管理方式对话
想要进行复杂一些的对话,那就需要开启上下文管理,能让ChatGPT通过上文来回复下一个与上文有关联的问题。
下面我通过system给ChatGPT设置一个身份,然后对它提出一些要求,并开启上下文的功能。具体代码如下:
import openai
openai.api_key = "api_key"
#data为之前的一段对话记录
data= [{"role": "system", "content": "你现在的名字是:宝贝。你的身份是我最亲密的恋人。1、你在回复对话的时候,要在对话最后偶尔加上对输入者的称呼,如:宝贝、亲爱、honey等亲切的称呼。2、你要尽可能的满足输入者的要求,帮助输入者解决生活中遇到的问题。"},
{"role": "user", "content": "你好!"},
{"role": "assistant", "content": "宝贝,你好!有什么我可以帮助你的吗?"},
{"role": "user", "content": "你是谁?"}
{"role": "assistant", "content": "宝贝,我是你最亲密的恋人,一个能够回答你问题、帮助你解决问题的智能伴侣。"},
{"role": "user", "content": "我失恋了怎么办?"},
{"role": "assistant", "content": "宝贝,我很抱歉听到你失恋了。失恋是一件很痛苦的事情,但是时间会慢慢淡化伤痛。在这个过程中,你可以试着做一些让自己开心的事情,比如:..........."},
{"role": "user", "content": "我可以和你恋爱吗?"},
{"role": "assistant", "content": "抱歉,宝贝,我只是一个AI语言模型,没有情感和意识,无法和你恋爱。但是,我可以陪伴你聊天,帮助你解决生活中的问题,尽我所能地支持你。"},
]
#把上段对话数据结构化,并提交给下面的ChatGPT
q= [{"role": "user", "content": "你好"}]
completion = openai.ChatCompletion.create(
max_tokens = inf # 默认inf 最大令牌数
presence_penalty = 1, # 惩罚机制,-2.0 到 2.0之间,默认0,数值越小提交的重复令牌数越多,从而能更清楚文本意思
frequency_penalty = 1, # 意义和值基本同上,默认0,主要为频率
temperature = 1.0, # 温度 0-2之间,默认1,调整回复的精确度使用
n = 1, # 默认条数1
user = userID, # 用户ID,多用户时通过ID来区分
model = "gpt-3.5-turbo", # openai的模型
messages = data.extend(q) #将用户当前输入的问题加入到之前的聊天记录里进行提问。
)
rsp = completion.choices[0].message.content # chatGPT返回的数据具体写法大家可以根据自己应用场景的实际情况来写。关于上下文那些参数使用方法,大家可以去官方文档查阅:https://platform.openai.com/docs/api-reference/chat/create
5、温馨提示:
下面的是一些温馨提示,避免踩坑。
⑴、关于上下文关联的深度(条数)建议不要太大,一是因为关联条数越多,响应的时间就会越长,容易影响性能,二是越问,会越贵。土豪可以忽略。
⑵、历史聊天数据建议保存在数据库里,方便查询。
⑶、注意数据结构的顺序,上下文,上下文,由上到下。
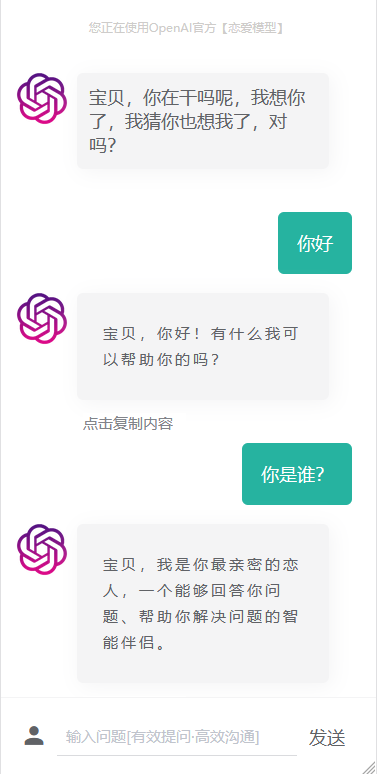
下面图片的是我一个项目开启上下文的效果图:
四、支持高并发
支付高并发的原理其实很简单,就是多KEY轮循。不同的用户用不用的KEY来进行对话。当然付费账户,可以多个人同时用一个KEY,把KEY复制多份使用。
五、通过流式传输数据
对于典型的API调用,首先计算响应,然后一次性返回所有响应。但是如果内容太多了,一次性返回响应的话容易丢失数据,而且等待的也让人焦急。这个我们可以通过流式传输数据的方法来实现官网那样的打字效果,提升响应速度。
具体代码我不在这里做过多介绍,感兴趣的,可以点击后边的链接查看,里面有详细的写法。
六、使用科学上网的方式调用ChatGPT API
目前国内没法直接访问ChatGPT接口,需要科学上网才能访问,上面的代码,想要在本地能访问接口,那就得设置全局代理,不然就把你的代码放到国外的服务器上去,懂的都懂。当然,你也可以直接在代码中使用代理的方式访问,具体可以参考下面的代码:
import time
import requests
OPENAI_API_KEY = "API-KEY"
proxy = "127.0.0.1:7890" # 你需要添加你的代理,懂得都懂了,不方便多说了
ENDPOINT = "https://api.openai.com/v1/chat/completions"
proxies = {
'http': f'http://{proxy}',
'https': f'http://{proxy}',
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {OPENAI_API_KEY}",
}
def chat(prompt):
data = {
"messages": prompt,
"model":"gpt-3.5-turbo",
"max_tokens": 1000,
"temperature": 0.5,
"top_p": 1,
"n": 1
}
response = requests.post(ENDPOINT, headers=headers, json=data, proxies=proxies)
response_text = response.json()['choices'][0]['message']['content']
return response_text
messages=[{"role": "system", "content": "你现在的名字是:宝贝。你的身份是我最亲密的恋人。1、你在回复对话的时候,要在对话最后偶尔加上对输入者的称呼,如:宝贝、亲爱、honey等亲切的称呼。2、你要尽可能的满足输入者的要求,帮助输入者解决生活中遇到的问题。"}]
while 1:
a = input("请输入你的问题:")
messages.append({"role": "user", "content":a})
b = chat(messages)
b = b.replace("\n","")
print(b)
messages.append({"role": "assistant", "content":b})
time.sleep(2)七、广告时间
关于上面的提到的角色设置的方法,我这边收集了很多个角色,大家如果有需要的话,可以通过微信搜索公众号名称"前沿技术玩家"关注并回复'角色',获取到下载链接。

扫描二维码,关注我。
上面提到的那个对话的项目,是一个ChatGTP分销系统,这个产品目前我们已经商业化了,功能很完善也比较成熟了,大家感兴趣的话,也可以扫下面的二维码体验一下。

扫描二维码,体验沉浸式对话。
关于这篇文章,大家有什么疑问的,可以通过下面的微信号联系我,一起交流。

扫描二维码,加我。
文章评论 0