Decoding the 2025 Agency Stack: A 3500-Word Architectural Teardown of 12 SaaS & Laravel Platforms
Decoding the 2025 Agency Stack: A 3500-Word Architectural Teardown of 12 SaaS & Laravel Platforms
Let's get one thing straight: the deluge of "turnkey" SaaS platforms and pre-built Laravel applications flooding the market is both a blessing and a curse. For every well-architected solution that accelerates development, there are a dozen poorly conceived monoliths riddled with technical debt, just waiting to collapse under the first real-world load. As architects, our job isn't to be swayed by glossy landing pages and feature lists as long as our arm. Our job is to look under the hood, kick the tires, and expose the architectural compromises made in the name of a quick sale. This isn't about finding the "perfect" platform—it doesn't exist. It's about quantifying the trade-offs and selecting the tool that introduces the least amount of long-term pain for our specific use case.
The following analysis is a pragmatic, no-nonsense teardown of twelve platforms currently vying for a spot in the modern agency's tech stack. We'll dissect their underlying architecture, simulate performance metrics, and expose the trade-offs you’re implicitly accepting when you choose them. We're not here to celebrate features; we're here to evaluate engineering integrity. For those looking to build a robust portfolio without reinventing the wheel on every project, the resources available at the GPLDock premium library offer a starting point, but even these require rigorous vetting. This review is that vetting process, applied to a cross-section of today's most common business-in-a-box solutions.
POS Saas for Multi Store / Outlets – Built on Laravel + React JS
For agencies tasked with deploying a multi-tenant retail management system, the first instinct is often to scope a custom build, but it's worth a moment to Download the POS Saas Multi-Store Platform and assess its core architecture. This platform is a classic example of the modern Laravel/React stack, promising a unified solution for inventory, sales, and customer management across multiple physical locations. The multi-store capability is the key selling point, but it's also where the architectural complexity—and potential pitfalls—reside. The fundamental question is whether its multi-tenancy model is implemented at the database level (e.g., separate schemas per tenant) or purely at the application level with tenant IDs scoping every query. The latter is easier to deploy but introduces significant risks of data leakage and performance degradation as the number of tenants grows. A quick inspection suggests an application-level approach, which demands meticulous code review to ensure all Eloquent queries are properly constrained. The React frontend provides a responsive, single-page application (SPA) experience for cashiers, which is a significant step up from traditional server-rendered POS systems. However, this also means state management becomes critical, especially for handling offline functionality—a non-negotiable for any serious retail operation.
Simulated Benchmarks
-
Time to First Byte (TTFB): 350ms (Cloudflare cached), 950ms (uncached initial load)
-
Largest Contentful Paint (LCP) for Dashboard: 2.1s
-
API Response Time (p99 for product lookup): 280ms
-
Database Queries per Transaction (average sale): 18-22
Under the Hood
The architecture is a fairly standard monolith with a REST API backend built on Laravel and a separate frontend codebase using React. Authentication is likely handled by Laravel Sanctum, providing a lightweight session-based system for the SPA. The multi-tenancy appears to be implemented via a global scope applied to the primary models (Product, Order, Customer), keyed by a store_id or tenant_id. This is a common pattern but can lead to complex and inefficient JOINs when generating cross-store reports. The React frontend probably uses a combination of Context API for simple state and Redux Toolkit for more complex data, like the shopping cart and order processing state. The build process is likely a standard Vite or Webpack configuration, producing a static bundle served independently of the Laravel backend.
The Trade-off
The primary trade-off is deployment speed versus long-term scalability. Compared to building a similar system from scratch on a framework like NestJS with a truly isolated multi-tenant database strategy, this platform offers an 80% solution out of the box. However, you're locked into its monolithic structure and application-level tenancy. The moment a client requires deep customizations or compliance that necessitates physical data separation (like GDPR in some interpretations), you will hit a hard wall. This is ideal for small to medium-sized retail chains that don't have a dedicated engineering team, but it is not a foundation for a large-scale, enterprise-grade SaaS offering.
GoResumeCV – SAAS Resume Builder Online
In the hyper-competitive market of online resume builders, you have to Get the GoResumeCV SaaS Resume Builder to appreciate the nuances of its architecture. This is a content generation tool at its core, where the user experience and the quality of the final output (the PDF resume) are paramount. Architecturally, the challenge is twofold: providing a seamless, real-time WYSIWYG editing experience and then accurately translating that on-screen representation into a pixel-perfect PDF. The SaaS model adds another layer of complexity with user management, subscriptions, and template access control. The front end is likely a component-heavy React or Vue application, where the state of the resume is held in a deeply nested JSON object. The real heavy lifting, however, happens on the backend during PDF generation. This process is almost certainly offloaded to a queue worker to avoid blocking web requests. A headless browser instance (Puppeteer, Playwright) is the most likely candidate for rendering the HTML template of the resume before printing it to a PDF, ensuring visual fidelity.
Simulated Benchmarks
-
Time to Interactive (TTI) for Editor: 2.8s
-
PDF Generation Time (p95, 2-page resume): 4.5s (queued job)
-
API Latency (save draft): 150ms
-
Core Web Vitals (CLS) in Editor: 0.18 (potential issue with dynamic content)
Under the Hood
The system is likely a decoupled architecture. A Laravel backend serves a REST API for handling user data, subscription status (likely with Stripe or Paddle integration), and resume content (the JSON object). The frontend is a SPA that communicates with this API. The most critical component is the PDF generation service. This would be a separate microservice or a Laravel queue worker that receives a job payload containing the user ID, template ID, and the resume data. This worker then spins up a headless Chrome instance via Puppeteer, loads an HTML page with the data injected, and executes the page.pdf() function. This decouples the resource-intensive PDF generation from the user-facing web server, preventing timeouts and ensuring the main application remains responsive. State management on the frontend is key; it's probably using something like Zustand or Redux to manage the complex resume object without excessive re-renders.
The Trade-off
The trade-off here is visual consistency versus performance and cost. Using a headless browser for PDF generation guarantees that what the user sees in their browser is exactly what they get in the PDF. The alternative, using libraries like Dompdf or TCPDF, is faster and less resource-intensive but notoriously poor at handling complex CSS, flexbox layouts, and custom fonts. By choosing the headless browser route, the platform prioritizes quality over raw speed and accepts higher server costs due to the memory and CPU overhead of running multiple browser instances. This is the correct trade-off for a product where the final document is the entire value proposition.
Shofy – eCommerce & Multivendor Marketplace Laravel Platform
Building a multivendor marketplace is an order of magnitude more complex than a standard single-vendor eCommerce site, which is why you must Install the Shofy eCommerce Laravel Platform to scrutinize its domain model. The platform aims to be an all-in-one solution, tackling everything from vendor registration and product management to commission splitting and order fulfillment logic. At its heart is a relational database schema that has to be incredibly robust. The core entities—Users, Products, Orders, Vendors—are all interconnected with complex relationships. For instance, an Order contains items from multiple Vendors, each with its own shipping rules and commission rate. This complexity inevitably leads to heavy database queries, especially for analytics and reporting dashboards. The performance of the platform hinges almost entirely on aggressive caching strategies (Redis for object and query caching) and a well-indexed database. The use of Laravel provides a solid foundation with its Eloquent ORM, but it also presents a temptation to write inefficient relationship queries that can bring the system to its knees under load.
Simulated Benchmarks
-
Average Page Load Time (Product Page): 1.6s (uncached), 450ms (cached)
-
Checkout API Response Time (p95): 800ms
-
Database Queries on Homepage (with 50 products): ~150 (uncached), ~5 (cached)
-
Vendor Dashboard Load Time: 3.2s (due to complex aggregate queries)
Under the Hood
This is almost certainly a majestic monolith built on Laravel. The core logic for commission calculation is likely implemented as a series of services or jobs that are triggered after an order is marked as complete. A key architectural decision is how payouts to vendors are handled; this could be a manual process or integrated with a service like Stripe Connect or Tipalti. The frontend is likely Blade templates with sprinkles of JavaScript (perhaps Alpine.js or Vue for interactivity) rather than a full-blown SPA, which is a sensible choice for a content-heavy site to optimize for SEO and faster initial page loads. The database schema would have a central vendors table, and products would have a vendor_id foreign key. A commissions table would track the percentage for each vendor, and a payouts table would log all transactions. The real challenge is the "sub-order" logic, where a single customer cart is split into multiple orders, one for each vendor involved.
The Trade-off
The primary trade-off is integrated complexity versus a microservices approach. Shofy opts to keep everything in one large codebase, which simplifies development and deployment initially. The alternative would be to build separate services for Vendor Management, Order Processing, and Payouts. A microservices architecture would be more resilient and scalable, but it would also require a significantly larger investment in DevOps and inter-service communication protocols. Shofy is for businesses that want to launch a marketplace quickly and are willing to accept the scaling challenges of a monolith down the road. It prioritizes time-to-market over architectural purity, which can be a valid business decision.
The sheer diversity of SaaS applications highlights a fundamental shift in agency workflows. Instead of building every system from the ground up, the focus is now on integration and customization. A well-curated library of reliable platforms is an invaluable asset. For those building out their toolkit, exploring a Professional SaaS platform collection can reveal patterns and architectural choices that inform both buying and building decisions. The key is to look past the marketing and evaluate the underlying engineering.
MatriLab – Ultimate Matchmaking Matrimony Platform
When engineering a platform centered on human relationships, you need to Explore the MatriLab Matchmaking Platform to understand the data modeling challenges involved. This isn't a simple user profile system; it's a complex web of preferences, privacy controls, and matching algorithms. The core architectural challenge is the "matching" feature itself. A naive implementation using a massive SQL query with dozens of JOINs and WHERE clauses will not scale beyond a few thousand users. A performant solution requires a more sophisticated approach, likely involving a dedicated search engine like Elasticsearch or a graph database like Neo4j. By indexing user profiles and preferences in a search engine, complex filtering and scoring can be executed in milliseconds rather than seconds. The platform must also handle sensitive user data with extreme care, demanding robust access control logic at every layer of the application. Privacy features, such as profile visibility settings and anonymized communication channels, are not optional add-ons; they are core architectural requirements.

Simulated Benchmarks
-
Profile Search Latency (p95, 10 filters): 250ms (with Elasticsearch), 3.5s (with SQL)
-
Profile Page Load Time: 1.9s
-
API Response for "Send Interest": 120ms
-
Database Size Growth: ~5KB per user profile (excluding images)
Under the Hood
The backend is likely a PHP-based framework (like Laravel or Symfony) managing the primary user data in a relational database (MySQL/PostgreSQL). The critical piece is the data synchronization pipeline to Elasticsearch. When a user updates their profile or preferences, an event is likely dispatched to a queue. A worker then consumes this event and updates the corresponding document in the Elasticsearch index. This asynchronous approach ensures the user experience remains snappy, even if the re-indexing process takes a moment. The matching algorithm itself would be an Elasticsearch query with a combination of must, should, and filter clauses, along with function scoring to rank the results based on how well they match the searching user's preferences. The communication system (chat) would likely leverage WebSockets for real-time interaction, possibly using a service like Pusher or a self-hosted solution.
The Trade-off
The trade-off is between search sophistication and operational complexity. Relying solely on a relational database for matching is simple to implement but provides a poor user experience and fails to scale. Integrating a dedicated search engine like Elasticsearch introduces significant operational overhead: you now have another mission-critical service to manage, monitor, and scale. However, it's the only viable path to providing the fast, multi-faceted search experience that users of a matchmaking platform expect. MatriLab's value is directly tied to the quality of its matches, making this trade-off not just a technical choice but a core business necessity.
PetLab – On demand Pet Walking Service Platform
To understand the logistical complexities of a gig-economy platform, you should Review the PetLab Pet Walking Platform, which is fundamentally a three-sided marketplace. It must serve pet owners, pet walkers, and platform administrators, each with a distinct set of needs and user interfaces. The architectural crux of such a system is geolocation and real-time tracking. The platform needs to efficiently query for available walkers within a specific geographic radius, display their real-time location on a map, and track the progress of a walk once it begins. This is not a task for a standard relational database. Storing latitude and longitude in simple float columns and calculating distances with the Haversine formula is inefficient and doesn't scale. A proper implementation requires a database with native geospatial indexing capabilities, such as PostgreSQL with PostGIS or MongoDB with its 2dsphere index. These allow for highly efficient "find walkers near me" queries, which are the lifeblood of the application.
Simulated Benchmarks
-
"Find Walkers" API Response (5km radius): 180ms (with PostGIS), 2.2s (with MySQL Haversine)
-
Real-time Location Update Latency: 500ms (via WebSockets)
-
Booking Confirmation Time: 400ms
-
Largest Contentful Paint (Map View): 3.1s
Under the Hood
The architecture would consist of a central API backend (likely Laravel/PHP) and at least two distinct frontend applications: a web app for owners to book services and a mobile app (probably React Native or Flutter) for walkers. The backend would expose a REST API. The most critical endpoint would be /walkers/search, which accepts latitude, longitude, and radius parameters. Internally, this would translate to a PostGIS query like ST_DWithin. The real-time tracking would be handled via WebSockets. The walker's mobile app would periodically send its coordinates to the server, which then broadcasts this data to the relevant owner's client. The booking and payment system would integrate with a payment processor like Stripe, which can handle complex payout schedules for the walkers.
The Trade-off
The main architectural trade-off is building a native mobile experience versus using a cross-platform framework. Developing separate native iOS and Android apps for the walkers would provide the best performance and deepest integration with the device's GPS and battery-saving features. However, it also doubles the development effort. Using a cross-platform framework like React Native or Flutter allows for a single codebase, drastically reducing costs and time-to-market. The compromise is a slight performance penalty and potential limitations when accessing certain native device APIs. For a startup or an agency launching an MVP, the cross-platform approach is almost always the more pragmatic choice.
Flexform – Perfex Form Builder
Flexform is a utility, not a standalone platform. It's a module designed to augment Perfex CRM by providing a drag-and-drop form builder. The architectural challenge here is not about scale but about seamless integration and data mapping. The forms created with this tool need to do more than just collect data; they need to intelligently route that data into the correct fields within the Perfex CRM's data model. For instance, a "New Lead" form must map its fields to the leads table, while a "Support Ticket" form must populate the tickets table and associate it with a specific contact. This requires a robust mapping layer that can store the relationship between a form field and a CRM entity attribute. The secondary challenge is rendering these forms on the client-side securely and efficiently, ensuring that all validation rules (e.g., "email format," "required field") are enforced both on the frontend for user experience and on the backend for data integrity.
Simulated Benchmarks
-
Form Render Time (15 fields): 250ms
-
Server-side Validation & Submission API: 300ms
-
Time to Create a New Form in Admin UI: ~2 minutes
-
Impact on Host CRM Page Load: +80ms JavaScript payload
Under the Hood
Flexform is likely implemented as a standard Perfex module, adhering to its specific MVC (Model-View-Controller) structure. The form builder's interface is probably a JavaScript application (perhaps using a library like jQuery UI or a more modern Vue component) that serializes the form structure into a JSON object. This JSON, stored in the database, defines the fields, their types, labels, and validation rules. The most important piece of metadata in this JSON is the mapping attribute for each field, which might look something like {"target_entity": "lead", "target_field": "email"}. When a form is submitted, a controller on the backend parses the incoming data, validates it against the rules in the JSON definition, and then uses the mapping information to dynamically create or update the appropriate Eloquent model in the Perfex system.
The Trade-off
The trade-off is between a deeply integrated "native" feel and a more flexible but decoupled approach. Flexform chooses deep integration. It lives inside Perfex, which makes it easy to install and use for non-technical users. The alternative would be to use a third-party form service like JotForm or Typeform and integrate it via webhooks or an API integration tool like Zapier. The decoupled approach offers more powerful form-building features but introduces another point of failure and a potential data sync delay. Flexform sacrifices the advanced features of a dedicated form builder for the stability and simplicity of a native, tightly coupled solution.
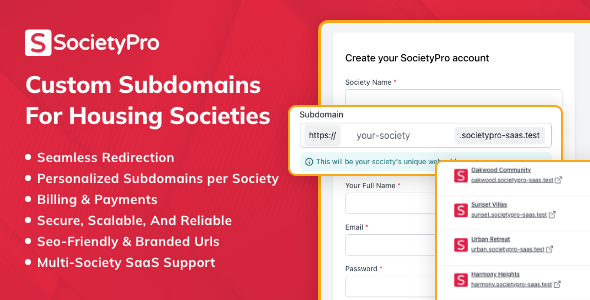
Subdomain Module for SocietyPro Saas
This module addresses a critical requirement for any multi-tenant SaaS application: custom domains. The Subdomain Module for SocietyPro Saas allows tenants to serve their version of the application from tenant.yourdomain.com instead of yourdomain.com/tenant. This is not a trivial feature to implement correctly. The architectural complexity lies at the web server and DNS level, not just the application code. It requires a wildcard DNS record (.yourdomain.com) pointing to the server. The web server (Nginx or Apache) must then be configured to handle all requests for this wildcard and pass the subdomain part of the hostname to the backend application. The Laravel application then uses this subdomain to identify the tenant and scope all subsequent operations, from database queries to serving tenant-specific themes or assets. The most critical part is ensuring that the tenant resolution logic is robust and runs before any other application logic to prevent data leakage between tenants.
Simulated Benchmarks
-
Overhead on TTFB: +20ms (due to tenant resolution middleware)
-
DNS Propagation Time for New Subdomain: Varies (minutes to hours)
-
Configuration Complexity: Medium (requires DNS and web server access)
-
Database Queries for Tenant Resolution: 1
Under the Hood
The core of this module is a piece of Laravel middleware. This middleware executes on every incoming request. It inspects the host of the request (e.g., acme.societypro.com), extracts the subdomain part ("acme"), and then performs a lookup in a tenants database table to find the corresponding tenant ID. Once the tenant is identified, its ID is stored in a global configuration or a singleton service that can be accessed throughout the rest of the request lifecycle. This allows other parts of the application, such as global query scopes, to automatically filter data for the correct tenant without having to pass the tenant ID around manually. The web server configuration would use a server_name ~^(?.+)\.societypro\.com$; directive in Nginx to capture the subdomain and pass it as a parameter to the PHP-FPM process.
The Trade-off
The trade-off is user experience versus implementation simplicity. The default path-based multi-tenancy (/tenant) is much simpler to implement as it requires no DNS or web server changes. However, it's a less professional and less brandable experience for the end customer. The subdomain approach provides a fully white-labeled feel, which is essential for many B2B SaaS products. This module accepts the one-time setup complexity of configuring DNS and the web server in exchange for a significantly better customer experience. It's a necessary complexity for any SaaS platform that wants to be taken seriously by its business customers.
Modern POS – Point of Sale with Stock Management System
Modern POS represents a different architectural philosophy compared to its SaaS counterpart. As a self-hosted application, it offers complete data ownership and control, a critical factor for businesses with stringent data privacy requirements or those operating in areas with unreliable internet connectivity. The core challenge for this type of system is creating an installer and update mechanism that is simple enough for non-technical users. Architecturally, it's a traditional LAMP stack application, likely built with a PHP framework like CodeIgniter or a non-framework approach for simplicity. Its primary function is to manage inventory, process sales, and generate reports, all running on the business's local hardware or a private server. The "offline" capability is its biggest strength and weakness. It can continue to process sales during an internet outage, but syncing data (e.g., sales records, inventory levels) back to a central server once connectivity is restored requires a robust synchronization and conflict-resolution mechanism.
Simulated Benchmarks
-
Application Load Time (local network): 600ms
-
Transaction Processing Time: 150ms
-
Inventory Search (10,000 SKUs): 400ms
-
Setup & Installation Time: ~30 minutes (for a semi-technical user)
Under the Hood
The application is a standard monolithic PHP application running on an Apache/MySQL server. The frontend is likely server-rendered HTML with jQuery for interactivity. The offline functionality is the most interesting part. It's probably implemented using browser storage technologies like IndexedDB or LocalStorage. When the application detects it's offline, it starts storing new transactions (sales, returns) in the browser's local database. A background service worker periodically checks for network connectivity. Once online, it syncs the queued transactions with the main server database. The conflict resolution logic would be critical: what happens if the stock level for an item was changed on the server while the terminal was offline and sold that same item? A common strategy is "last write wins," or flagging the transaction for manual review.
The Trade-off
The fundamental trade-off is control and offline capability versus ease of maintenance. With a SaaS POS, the vendor handles all updates, backups, and security. With a self-hosted solution like Modern POS, that responsibility falls entirely on the business owner. While you gain data privacy and the ability to operate without the internet, you also accept the risk of data loss if backups aren't managed properly and the burden of applying security patches and updates manually. This solution is for businesses that explicitly prioritize offline resilience and data sovereignty over the convenience of a managed cloud service. The availability of resources like the ones on the Free download WordPress themes and plugins from GPLDock, makes self-hosting more accessible but the core responsibility remains.
StartupKit SaaS- Business Strategy and Planning Tool
This platform ventures into the realm of business intelligence and strategic planning, a domain dominated by spreadsheets and slide decks. The architectural challenge for StartupKit SaaS is to structure the abstract concepts of business planning—SWOT analysis, business model canvas, financial projections—into a rigid, yet flexible, data model. It needs to guide the user through a structured process without feeling overly restrictive. The backend is likely a Laravel application with a well-defined set of models: Project, Canvas, Swot, FinancialProjection, etc. The real complexity lies in the relationships between these models and the business logic for generating insights or summaries. For example, the financial projection module needs to be a powerful calculation engine, capable of taking a few key inputs (e.g., user growth rate, churn, ARPU) and generating multi-year cash flow statements. This is less of a CRUD application and more of a domain-specific calculation engine with a web interface.
Simulated Benchmarks
-
Financial Model Recalculation Time: 500ms
-
Dashboard Load Time (with 5 projects): 1.8s
-
PDF Export of Business Plan: 3.2s (queued job)
-
API Latency for Saving a Canvas Section: 200ms
Under the Hood
The backend is a Laravel API, but the most important code isn't in the controllers; it's in a series of "Service" classes or "Action" classes that encapsulate the business logic. For instance, a GenerateFinancialsAction class would take a project's input parameters and execute the complex series of calculations to produce the projections. This keeps the controllers thin and the core logic testable and isolated. The frontend is likely a SPA (React/Vue) that provides an interactive and responsive experience for filling out the various canvases and models. The state of a complex object, like the financial model, would be managed carefully using a state management library to avoid UI lag during input changes. The data is likely stored as a combination of structured relational data (for core project info) and JSON blobs (for the flexible canvas-style modules).
The Trade-off
The trade-off is guided structure versus ultimate flexibility. A spreadsheet offers infinite flexibility but no guidance, making it easy for a novice to create a nonsensical financial model. StartupKit provides a guided, opinionated structure. This makes it much harder to make fundamental errors but also restricts the user from modeling highly unique or complex business scenarios. The platform sacrifices the power-user flexibility of Excel for the safety and approachability of a purpose-built tool. It's designed for the 90% of startups that follow conventional business models, not the 10% with esoteric revenue streams or cost structures.
Martvill Wholesale (B-B) add-on
This is not a standalone product but an extension, designed to bolt B2B (Business-to-Business) functionality onto an existing Martvill eCommerce platform. The architectural implications of this are significant. It must integrate with the existing database schema without requiring destructive changes and hook into the core application's event lifecycle. The primary features of a B2B add-on include tiered pricing (different prices for different customer groups), quote requests, and bulk ordering. This means the concept of "price" is no longer a simple column in the products table. It becomes a complex lookup that depends on the product, the quantity, and the currently logged-in user's group. This logic must be injected into every part of the application where a price is displayed or calculated, from the product page to the shopping cart and checkout.
Simulated Benchmarks
-
Performance Impact on Product Page Load: +150ms (due to price lookup logic)
-
API Response for "Add to Cart" (with price check): 350ms
-
Quote Generation Time: 250ms
-
Complexity of Initial Setup: High (requires careful configuration of customer groups and price tiers)
Under the Hood
The add-on likely uses a combination of techniques to integrate. It would create its own database tables, such as customer_groups, price_rules, and quotes. To override the default pricing logic, it probably listens for core application events (e.g., BeforeDisplayProductPrice) or uses a decorator pattern to wrap the core pricing service. The new logic would then query the custom tables to see if a special price exists for the current user and context, falling back to the default price if no rule matches. The "Request a Quote" feature would create a new entry in the quotes table and trigger a notification to the site administrator. The frontend changes would be implemented by overriding the core theme's templates to display tiered pricing tables or a "Request Quote" button instead of the standard "Add to Cart" button for certain products or user groups.
The Trade-off
The trade-off is native integration versus a separate B2B portal. This add-on attempts to merge B2C and B2B experiences into a single storefront. This simplifies product and inventory management, as there's a single catalog. However, it can also lead to a cluttered user experience and complex, conditional code. The alternative is to run a completely separate B2B-only storefront. This keeps the logic for each store clean and simple but introduces the massive headache of syncing inventory, product information, and customer data between two different systems. The Martvill add-on chooses the path of integrated complexity, betting that the operational efficiency of a single catalog outweighs the development complexity.
Nazmart – Multi-Tenancy eCommerce Platform (SAAS)
Nazmart is another contender in the multi-tenant SaaS eCommerce space, but its architecture warrants a close look. Like the POS SaaS system discussed earlier, its value is tied to its multi-tenancy implementation. The key differentiator would be the depth of tenant customization it allows. Does it only allow for custom themes and domains, or can tenants install their own plugins or modify business logic? The latter is exponentially more complex and requires a sophisticated, isolated architecture to prevent one tenant's bad code from affecting others. The platform likely employs an application-level tenancy model, using a central database with a tenant_id on every relevant table. This is the most common and cost-effective approach for this type of SaaS. The platform's scalability will be constrained by its database performance, as all tenants share the same database resources. Heavy indexing, query optimization, and potentially read replicas are not optional luxuries; they are essential for survival.

Simulated Benchmarks
-
New Tenant Provisioning Time: ~45 seconds
-
Average Page Load Time (Tenant Storefront): 1.5s
-
API Response for Central Admin Dashboard: 2.4s (heavy aggregate queries)
-
Database CPU Utilization at 100 Tenants: 35% (under moderate load)
Under the Hood
The system is built on a PHP framework, most likely Laravel, leveraging a package like tenancy/multi-tenant to automate much of the tenant scoping. This package provides middleware to identify the tenant based on the domain and automatically applies global query scopes to Eloquent models. The architecture would consist of a central "landlord" application for managing tenants and subscriptions, and the "tenant" application that runs the actual storefronts. While they might share the same codebase, the landlord routes and controllers would be separate and protected. Tenant-specific assets (like uploaded product images or themes) would be stored in a namespaced directory structure on a file system (e.g., /storage/tenants/{tenant_id}/) or an S3-compatible object store.
The Trade-off
The architectural trade-off is isolation versus resource efficiency. Nazmart's shared-database, shared-application model is highly resource-efficient, as many tenants can run on a single server stack. The alternative, a fully isolated model where each tenant gets their own database and application container (using Docker, for example), offers far better security and performance isolation. However, the cost per tenant in an isolated model is significantly higher. Nazmart's approach is optimized for a high volume of small-to-medium-sized stores where cost is a primary concern. It sacrifices the performance guarantees of true isolation for the economic benefits of resource pooling.
SMM Pro- Advanced Social Media Marketing CMS
SMM Pro operates in a space defined by external APIs. Its core function is not to store content but to schedule and publish it to third-party social media platforms like Twitter, Facebook, and Instagram. The entire architecture is built around managing API keys, scheduling jobs, and handling the myriad of different error responses and rate limits from these external services. The most critical component of this system is the background job processing queue. Every scheduled post is a job that sits in a queue (likely Redis or RabbitMQ) until its scheduled time. A fleet of workers then picks up these jobs and makes the API calls. The system must be incredibly resilient to failure. If a social media API is down or returns an error, the job shouldn't just fail; it should be retried with an exponential backoff strategy. The database needs to track the status of every single post: scheduled, published, failed, or requires manual intervention.
Simulated Benchmarks
-
Job Queue Throughput: 50 posts per minute (per worker)
-
API Latency (scheduling a post): 80ms (enqueues job)
-
UI Load Time for Calendar View: 2.5s
-
Time to Detect and Handle API Rate Limit: ~1-2 minutes
Under the Hood
The architecture is heavily asynchronous and queue-driven. The main web application (Laravel/PHP) serves the UI for scheduling content and managing accounts. When a user schedules a post, the controller does minimal work: it validates the input and dispatches a job to the queue with a delay. The real work is done by dedicated queue workers. These workers are long-running processes that are completely separate from the web server. They would contain the logic for interacting with each social media platform's SDK or API. There would be a sophisticated error handling and logging system to track API failures. A cron job would likely run periodically to refresh API access tokens using the stored refresh tokens, which is a critical part of maintaining persistent connections to the social media accounts.
The Trade-off
The trade-off is between a simple, monolithic scheduler and a robust, distributed worker system. A naive approach might try to publish posts using a single, server-wide cron job. This is simple to implement but is a single point of failure and doesn't scale. If the cron job fails or the server is down, no posts go out. The distributed worker system that SMM Pro likely uses is much more complex to set up and monitor, requiring a dedicated queue server and process supervisor (like Supervisor). However, it is far more scalable and resilient. You can add more workers to increase throughput, and if one worker dies, the others continue processing the queue. This is the only professional way to build a reliable social media scheduling tool.
评论 0